近日,东南大学数学学院虞文武教授团队在分布式多智能体强化学习研究中取得新进展,研究成果以“Distributed Neural Policy Gradient Algorithm for Global Convergence of Networked Multi-Agent Reinforcement Learning ”为题在国际顶级期刊《IEEE Transactions on Automatic Control》上发表。
随着人工智能的逐渐兴起,多智能体系统技术的不断发展,结合了多智能体系统和强化学习的多智能体强化学习受到了越来越多的关注。近年来,多智能体强化学习已逐渐成为了人工智能领域以及控制优化领域的研究热点,并被广泛应用于智能电网、资源分配、交通信号控制以及自动驾驶等多类现实场景中。尽管基于神经网络近似的深度多智能体强化学习在众多场景中展现了显著的学习性能,但其非线性结构可能导致算法呈现非凸特性甚至出现发散现象。因此,关于神经网络近似下的多智能体强化学习算法的收敛性分析仍需进一步研究。
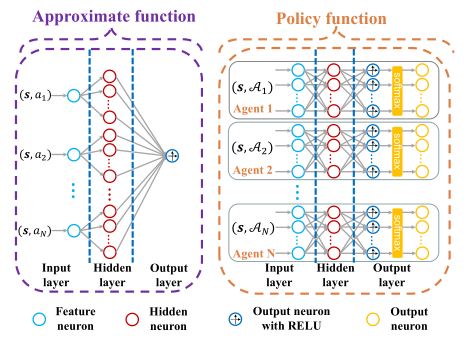

图1.神经网络结构 图2.算法结构
该工作针对网络化多智能体强化学习问题,基于兼容函数近似思想为智能体的近似Q函数和策略函数构建了两种新颖的神经网络结构,并提出了一种分布式神经策略梯度算法,解决了深度多智能体强化学习收敛分析难的瓶颈问题。该算法主要由分布式critic和分散式actor两部分组成。在分布式critic中,智能体通过通信网络与邻居智能体交互近似Q函数参数,实现对联合策略的协同评估;在分散式actor中,智能体利用近似Q函数估计策略梯度更新策略参数,实现对目标函数的优化。此外,该工作严格证明了所提出的分布式神经策略梯度算法的全局收敛性。
本文第一作者戴鹏程,2023年毕业于东南大学并获得理学博士学位(师从虞文武教授),通讯作者为东南大学数学学院虞文武教授。该工作由国家重点研发计划、国家自然科学基金、江苏省应用数学科学研究中心等项目资助。
文章链接:https://ieeexplore.ieee.org/document/11003569
